This post offers a deep dive into the abstractions and inner workings that power modern file systems.
Filesystem Abstractions
Filesystems provide two foundational abstractions for persistent storage: files and directories. A file is a linear array of bytes identified by an inode, which serves as its low-level name. The operating system does not interpret the contents of a file—it simply ensures the data is reliably stored and retrieved. Access to files is granted through file descriptors, allowing processes to read from or write to the file without knowing the underlying mechanics.
Directories serve as structured containers for organizing files and other directories into a hierarchical tree. Each directory maps human-readable names to inode numbers, enabling users and programs to navigate and reference files using paths like /foo/bar.txt. This hierarchy starts from the root (/) and supports nested structures, offering a scalable and intuitive naming system across storage devices and even virtualized resources like devices and pipes.
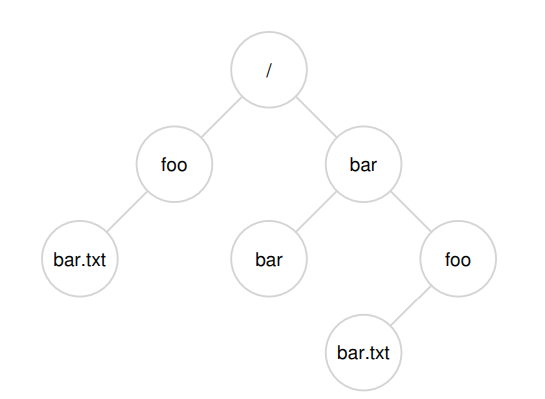
Image Source: Operating Systems Three Easy Pieces
Filesystem Interface
Interacting with a filesystem begins with a handful of core system calls. The open() call is used to create or access a file, returning a file descriptor that represents the file in the process’s descriptor table. Once a file is open, read() and write() allow data to be retrieved from or written to the file, while close() releases the descriptor once operations are complete.
These basic calls form the foundation of file I/O, providing a simple but powerful interface that abstracts away the complexity of underlying disk operations. Together, they enable everything from reading configuration files to logging application data, all through a consistent and unified API. Of course, there are more systemcalls than these ones, allowing the processes to access files in a more flexible manner.
Files and Directories on Disk
Under the hood, a filesystem organizes disk space into fixed-size blocks (e.g., 4KB), and divides them into several regions: the superblock, bitmaps, inode table, and data blocks. The superblock holds metadata about the filesystem itself—like the total number of inodes and blocks—while bitmaps track which inodes and blocks are free or in use.
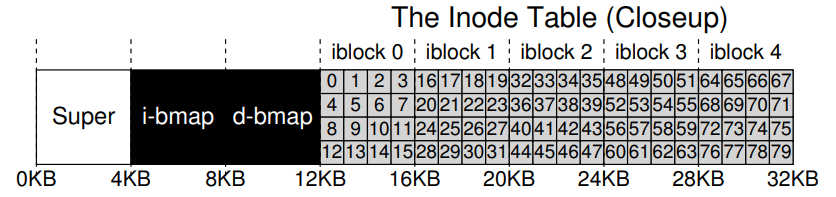
Image Source: Operating Systems Three Easy Pieces
Each file is represented by an inode, which stores metadata (size, timestamps, ownership) and pointers to its data blocks. Small files are mapped directly via direct pointers, while larger ones use indirect blocks—blocks that store more pointers—allowing scalable growth through single, double, or even triple-indirect references. For example, with 12 direct and one indirect pointer, a file can span thousands of blocks.
Directories are just special files that contain a list of (name, inode number) pairs. For example, the directory /foo/ might map "bar.txt" to inode 42. These mappings are stored in the directory’s data blocks and are read during path traversal. Internally, even the root directory is just an inode (usually inode 2), and the structure stays consistent whether the entry points to a file or another directory.
Conclusion
Filesystems are more than just a way to store files—they are carefully structured systems that manage space, ensure data reliability, and provide efficient access through simple interfaces. By understanding inodes, block layouts, and how files and directories are organized on disk, you gain a clearer view of what happens behind every open(), read(), or write().
This post is based on material from the excellent book “Operating Systems: Three Easy Pieces” (OSTEP) by Remzi and Andrea Arpaci-Dusseau.